Originally posted on Towards Data Science
Introduction
In this post, I will explain Long short-term memory network (aka . LSTM) and How it’s used in natural language processing in solving the sequence modeling task while building an Arabic part-of-speech tagger based on Universal Dependancy Tree Bank. This post is part of a series in building a python package for Arabic natural language processing.
The problems
Context ignorance
When working on a text data the context of this text matters and can’t be ignored. In fact, words have different meanings based on the context. If we looked at the task of machine translation. Context really matters here while the classical methods will ignore it.
If we are to write a translation method that takes an English sentence and return it translated into Arabic. The naive approach is to take every word from the original sentence and convert it into the target sentence. This approach will work but it will give no regards to any grammar or context.
Part-of-speech tagging
Part of speech tagging is the task of labeling each word in a sentence with a tag that defines the grammatical tagging or word-category disambiguation of the word in this sentence.
The problem here is to determine the POS tag for a particular instance of a word within a sentence.
This tags can be used to solve more advanced problems in NLP like
Language Understanding because knowing the tags means helps in obtaining a better understanding of the text as different words can have different meaning based on their location within the sentence. Text-to-speech and automated speaking tone control. Ignoring the context when tagging words will only result in the baseline of acceptance as the approach would tagging each word with the most common tag associated with this word from the training set.
So what we are trying to accomplish here is to overcome this issue and find an approach that doesn’t ignore the context of the data.
Deep learning Approach
Sequence modeling and RNNs
More specifically the issue we are trying to solve known as sequence modeling. Where we are trying to model sequential data like text or sound and learn to model it.
Sequence modeling or Sequence-to-sequence modeling was first introduced by Google Translation Team.
In general, Neural Networks are pattern recognition models which learn and enhance by iterating over the dataset and get better in recognizing patterns within the data.
Recurrent Neural Network is designed to prevent neural networks from decay by using feedback loops. Those feedback loops are what makes RNN better at solving the sequence learning task.
RNNs works more similar to a human brain than feedforward networks do. Because the human brain thinks persistently. So, when you are reading this post each word affects your understanding of the post you don’t throw away previous words from your memory to read a new word.
The mechanism of Recurrent neural networks
RNNs address the context of context by using memory units. The output that the RNN produce at step is affected by the output from the step. So in general RNN has two sources of input. One is the actual input and two is the context (memory) unit from previous input.
Mathematically,
Feedforward networks are defined by the formula.
The new state is a function of the weights matrix multiplied by the input vector
The result of this multiplication is then passed to the method called Activation function. which produce the final result.
The same process is applied in Recurrent network with a simple modification.
The previous state is first multiplied by a matrix
called hidden-state-to-hidden-state matrix then added to the input of the activation function
So won’t be only affected by but all the previous hidden states that has affected which will ensure the persistence of memory.
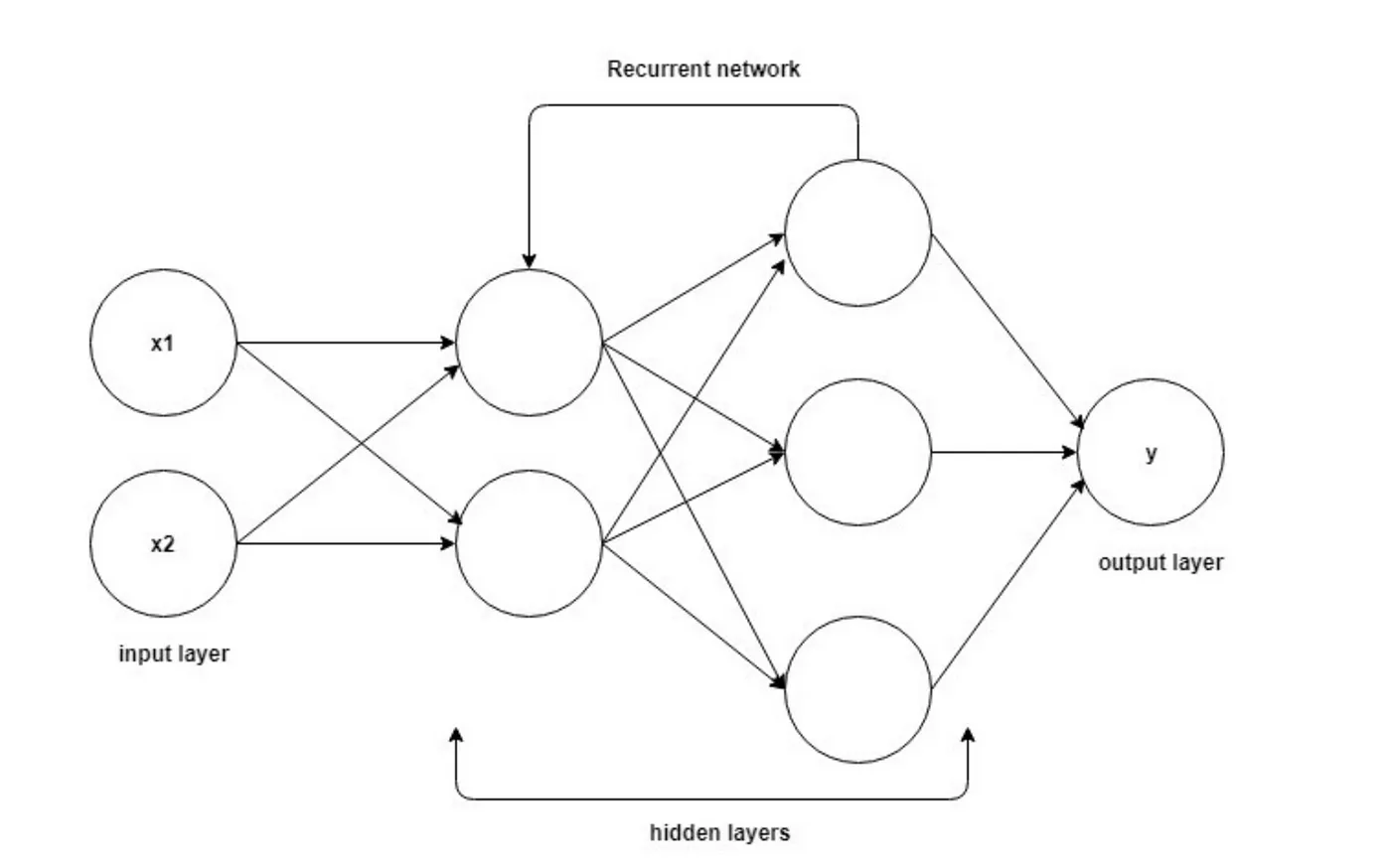
A normal RNN network will contain a single neural network layer which makes it unable to learn to connect long information. This issue is also known as Long-term Dependencies.
Long Short-Term Memory Architecture
RNNs are great. They helped a lot in solving many tasks in NLP. Still, they have the issue of Long-Term Dependencies.
you can read more about LTD in Colah’s great blog post here
LSTMs are designed to solve the LTD issue by remembering information for a longer time than RNN.
The only difference between RNN and LSTM that instead of having a single neural network layer in RNN. We have 4 NN layers in LSTM interacting together in a special way.
A step-by-step LSTM
An LSTM layer consists of a chain of cell states where each state consists of 4 main layers and 3 gates.
Now let’s walk through an LSTM cell state step by step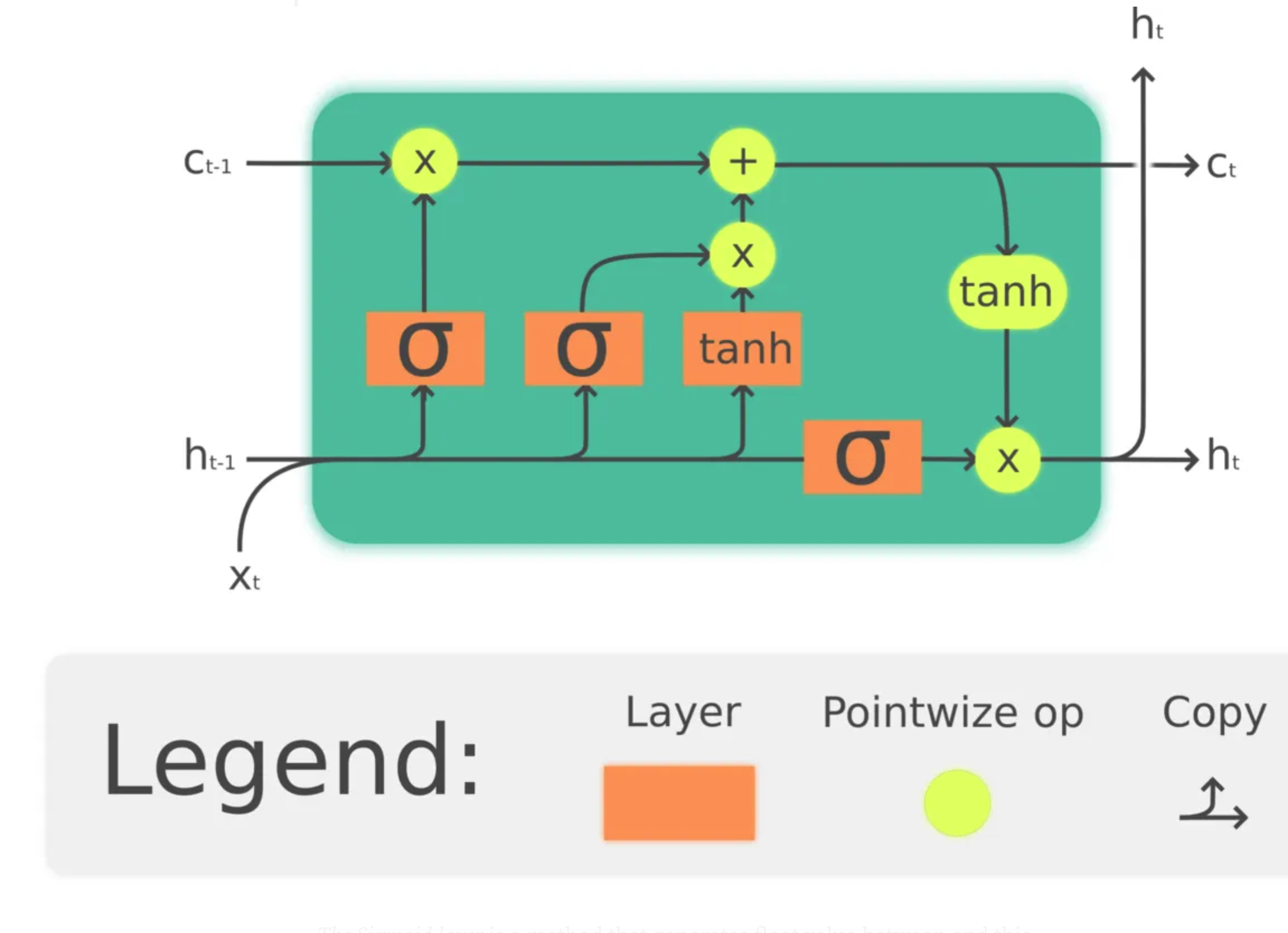
The core of a cell state is the horizontal line that connects between and. This line is where the data flow happens to throw the chain of the cell states. It’s very easy for the data to flow with minimum linear operations or unchanged this whole process is controlled by Gates.
Gates are what control the change of the data. They change the data optionally with a sigmoid neural layer and a vector multiplication operation.
The Sigmoid layer is a method that generates float value between and this value control how much data will be passed through the gate. means nothing while $One $ means all.
The first step is that the sigmoid layer decides what information to pass from the result of multiplying by. We can represent this operation mathematically like this:
The previous step did decide what data it’ll forget and what data it’ll carry on. In the second step, we need to actually do this.
We take the previous result and multiply it by the old state.
The old state is computed using the Tanh activation function. Multiplying the sigmoid by the tanh will decide which information the network forget and which get. Mathematically:
Finally, we need to decide what is the value of
Those operations are applied sequentially on the chain of cell states. Looking at the mathematical model of an LSTM can be intimidating so we are going to move to the applied part and implement an LSTM model with Keras for POS-tagger for the Arabic language.
Building an Arabic part-of-speech tagger
now as we walked through the idea behind deep learning approach for sequence modeling. We will apply that to build an Arabic language part-of-speech tagger.
For English language, PoS tagging is an already-solved-problem. For a reach morphological language like Arabic. The problem still persists and there is ZERO open sources deep-learning based Arabic part-of-speech tagger. Our goal now is to use what’ve learned about LSTMs and build an open source tagger.
The Data
The lack of open source tagger is an obvious result of the lack of an Arabic treebank dataset.
The well-known Penn TreeBank costs around 3k$ and the Quranic Treebank is very classical and perform poorly on day-to-day words.
Universal Dependencies (UD) is a framework for cross-linguistically consistent grammatical annotation and an open community effort with over 200 contributors producing more than 100 treebanks in over 70 languages Including Arabic
Data Preprocessing
UD provides the data set in CoNLL form. We can use pyconll to convert the dataset from CoNLL format into pandas data frame.
We need our data to be sequentially structured. So we need it in the following shape
[
[(Word1, T1), (Word2, T2), ...., (WordN, TM)], # Sentence one
[(Word1, T1), (Word2, T2), ...., (WordN, TM)], # Sentence two
.
.
.
[(Word1, T1), (Word2, T2), ...., (WordN, TM)] # Sentence M
]
Now as the data set is structured in a useful way. We want to encode our text data to numerical values.
This process is known as WordEmbedding.
The idea is simple, we give each word in our data a unique integer value. And substitute with this value in the data set so we can do pointwise operations on the data.
So before implementing the model, we have two WordEmbeddings word2index and tag2index. Which encode the words and the part-of-speech tags
Because we are doing seq2seq task which requires the input and the output to be fixed. The data should be transformed such that each sequence has the same length. This vectorization allows the LSTM model to efficiently perform batch matrix operation.
We can do this in Keras by adding 0’s to the shorter sentences until all our sentences have the same lengths.
The problem is that the model will be able to predict those values easily. So the accuracy will be very high even if the model didn’t predict any tag correctly.
So we will need to write our own accuracy metrics that ignores those paddings predictions.
Keras implementation of LSTM
After converting the data to a suitable shape. The next step was to design and implement the actual model.
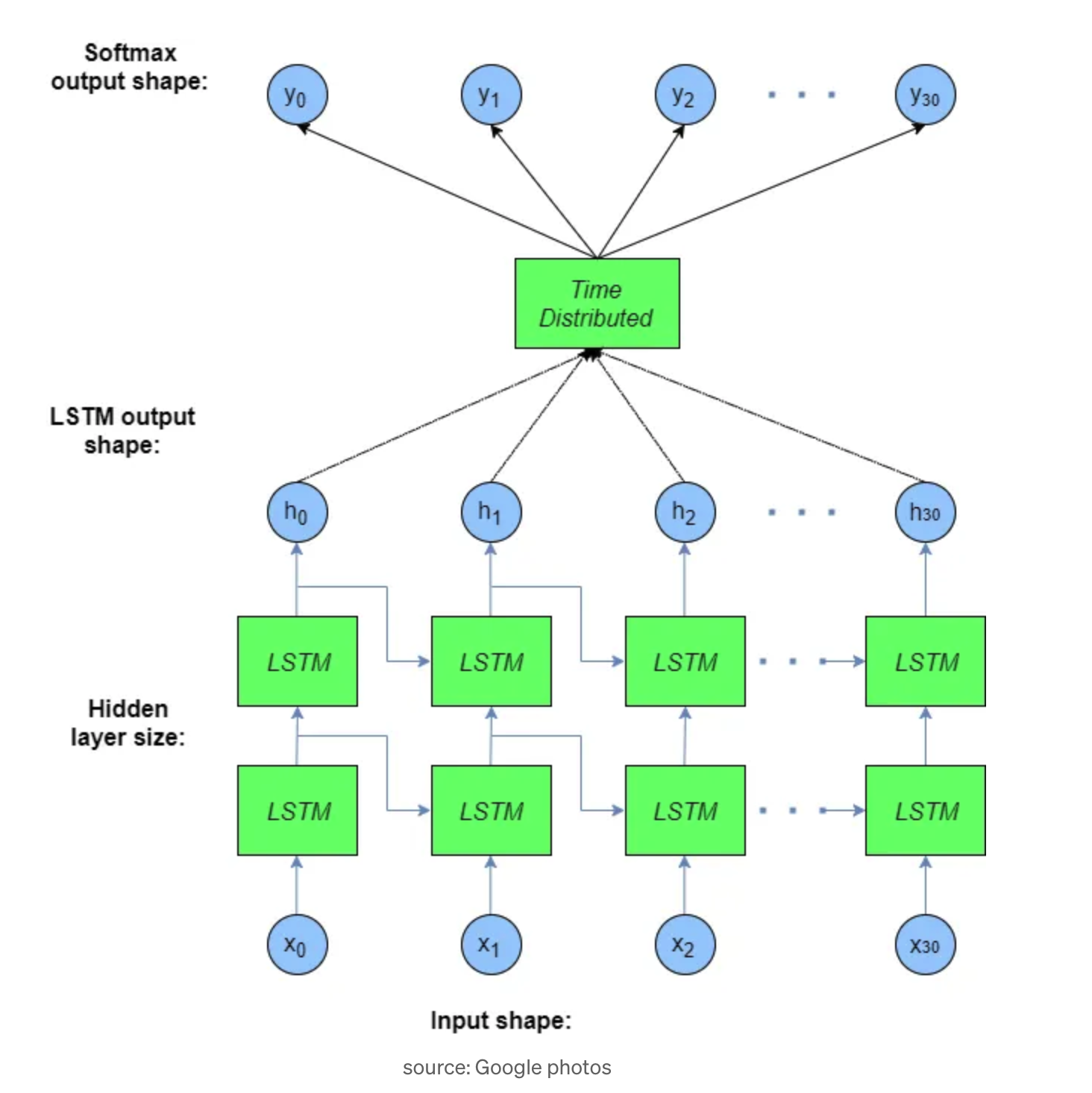
model structure
Now let’s explain the model thoroughly,
InputLayer is the first layer of the model. Keras has fixed size layer as explained in the preprocessing part so we define this layer with the maximum length of a sequence in the training set.
Embedding The embedding layer requires that the input data be integer encoded so that each word is represented by a unique integer. It is initialized with random weights then it will learn for each word in the dataset
LSTM The LSTM encoder layer is a sequence-to-sequence layer. It provides a sequence output rather than an integer value. And return_sequences force the layer to make the previous sequence input for the next one.
Bidirectional Bidirectional wrapper duplicates the LSTM layer so we have two side-by-side layers that transfer the resulted sequences to the inputted one. In practical this approach has a great effect on the long short-term memory. I used the default merge mode [concat] for the Bidirectionallayer.
TimeDistributed Dense layer is used to keep one-to-one relations on input and output layers. It applies the same Dense (fully-connected) operation to every timestep of a 3D tensor.
Activation The activation method for the Dense layer. We could’ve defined the activation method as a parameter in the Dense layer but the second one is a better approach*
check the full source code here github.com/adhaamehab/arabicnlp
Testing
This unittest is used to use the end to end model
1import unittest
2import arabicnlp
3
4
5class IntegrationTest(unittest.TestCase):
6 """Integration test for package interface"""
7
8 testtext = ""
9
10 def test_tokenization(self):
11 self.assertTrue(arabicnlp.tokens(self.testtext))
12
13 def test_stemming(self):
14 self.assertTrue(arabicnlp.stem(self.testtext))
15
16 def test_tags(self):
17 self.assertTrue(arabicnlp.tags(self.testtext))
18
19 def test_spelling(self):
20 self.assertTrue(arabicnlp.correct(self.testtext))
21
22 def test_sentiment(self):
23 self.assertTrue(arabicnlp.sentiment(self.testtext))
24
25 def test_similarity(self):
26 self.assertTrue(arabicnlp.similarity(self.testtext, self.testtext))
27
28
29class UnitTest(unittest.TestCase):
30 """Unit test here"""
31 def test_correction(self):
32
33 result = []
34 cases= {'توصية' : 'تتتتتتتتوصية' , 'الهام' : 'الهم', 'املائية' : 'املاءية' }
35 for _, val in cases.items():
36 result.append(arabicnlp.correct(val))
37
38 self.assertEqual(cases.keys(),result)
39
40 def test_stemming(self):
41 dictionary = {
42 "فليكن عندك الشجاعة لتفعل بدلاً من أن تقوم برد فعل " : "فلك عند شجع فعل بدل من ان تقم برد فعل",
43 "محمود و مهاب اصحاب منذ الطفولة" : "حمد و هاب صحب منذ طفل",
44 "المَدّ و الجَزْر يحدثان في البحر" : "الم د و الج ز ر حدث في بحر",
45 "لا يتوقف الناس عن اللعب لأنهم كبروا، بل يكبرون لأنهم توقفوا عن اللعب" : "لا وقف لنس عن لعب أنهم كبرو ، بل كبر أنهم وقف عن لعب",
46 "فهرس مقالات عربية رائعة" : "هرس قال عرب رئع",
47 "سينتقل من خلالها من روضة أنيقة إلى روضة ثانية" : "نقل من خلل من روض جمل الى روض ثني",
48 "كما أن بعض تلك المقالات قد خرجت في طباعة رديئة" : "كما ان بعض تلك قال قد خرج في طبع ردئ",
49 "تختصر عليه كثيراً من الوقت والجهد" : "خصر عليه كثر من الق جهد",
50 "بسم الله الرحمن الرحيم" : "بسم الل رحم رحم",
51 " تشتمل على أبواب متفرقة" : "شمل على بوب تفرق",
52
53 }
54
55 result_list = []
56
57 for key, value in dictionary.items():
58 result_list.append(self.__lemmas_checker(key, value))
59 return self.assertTrue(all(result_list), True)
60
61 def __lemmas_checker(self, test_str, correct_string):
62 """"
63 Checking if the Algorithm's output matches the correctly initialzied values
64 """
65 result_string = arabicnlp.stem(test_str)
66 if result_string == correct_string:
67 return True
68 return False
69
70 def test_tokens(self):
71 """Tests for the tokenizer"""
72 cases = {
73
74 "وقد تتكون النجوم في أزواج تدور حول بعضها البعض، مثال على ذلك نجده في نجم الشعرى اليمانية.":
75 ["و","قد","تتكون","النجوم","في","أزواج","تدور","حول","بعضها","البعض","،","مثال"
76 ,"على","ذلك","نجده","في","نجم","الشعرى","اليمانية","."],
77
78 "يبلغ عمر كوكب الأرض حوالي 4.54 مليار سنة (4.54 × 109 سنة ± 1%).":
79 ["عمر","الأرض","حوالي","4.54","مليار","سنة","(","4.54"
80 ,"×","109","سنة","±","1","%",")","."]
81 }
82
83 for case, correct in cases.items():
84 res = arabicnlp.tokens(case)
85 self.assertEqual(len(correct),len(res))
86
87 for i in range(len(correct)):
88 self.assertEqual(correct[i],res[i])
89
90 def test_tags(self):
91 text = "وقد تتكون النجوم في أزواج تدور حول بعضها البعض، مثال على ذلك نجده في نجم الشعرى اليمانية."
92 self.assertGreater(len(arabicnlp.tags(text)), 0)
93
94if __name__ == '__main__':
95 unittest.main()
Results
The training steps took around 40 mins on a 2017 MacBook Pro with 2.5 GHz CPU and 8 GB Ram.
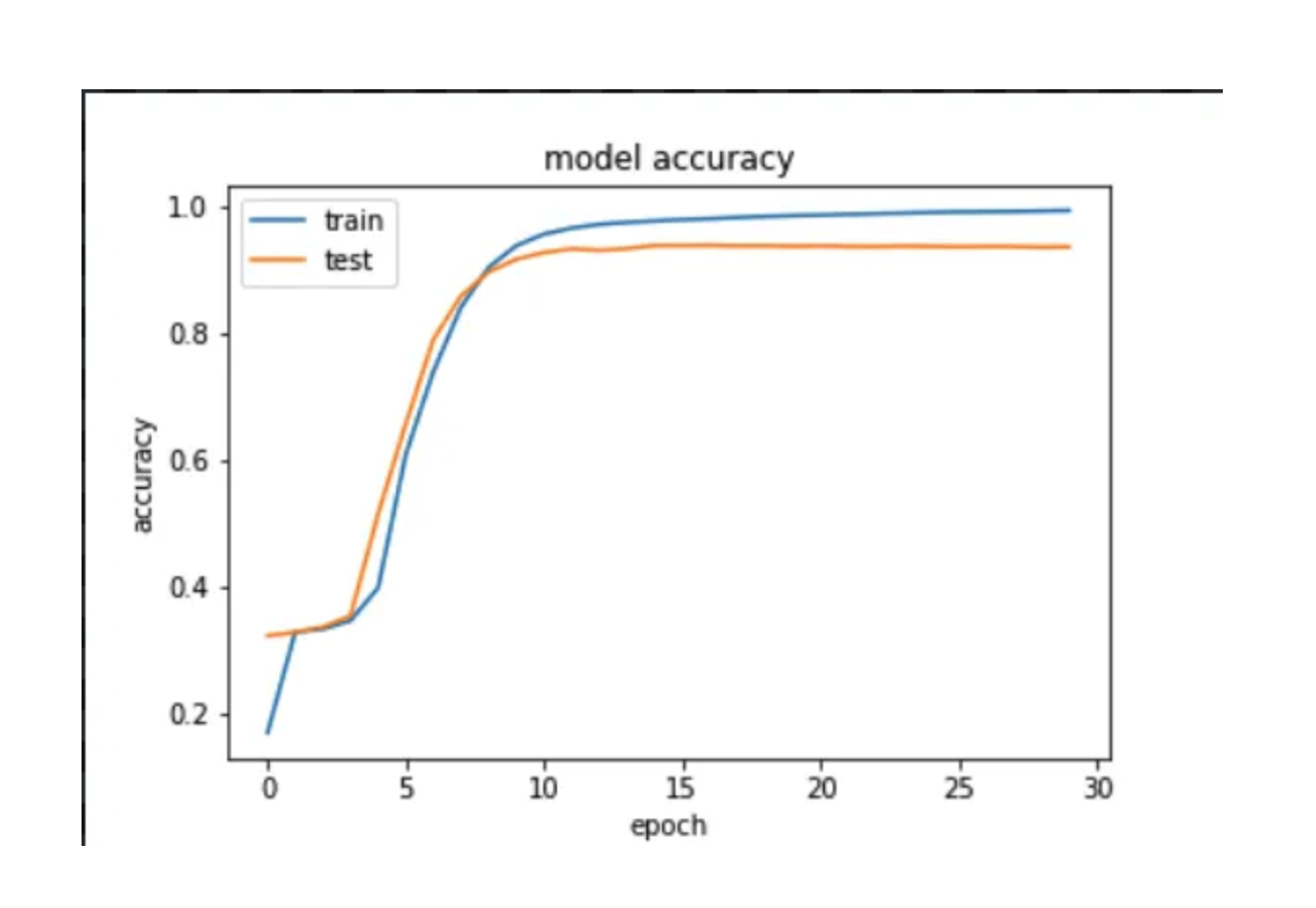
After we train our model we evaluate and visualize the training process it.
Model Accuracy
Model Loss
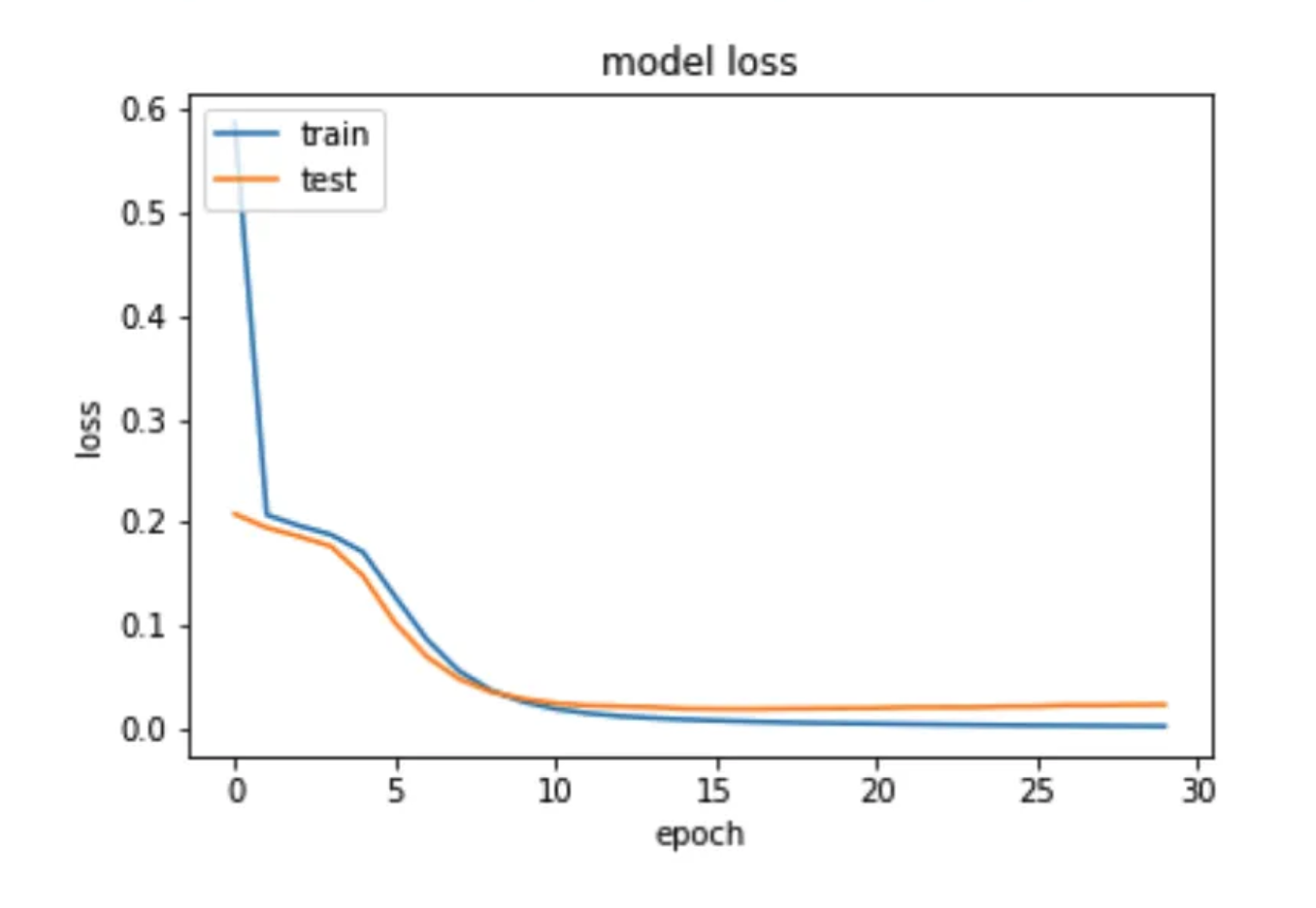
The model has reached 0.916 and started to converge after 30 epochs
In the evaluation we used stochastic gradient descnet as it performs better than Adam in the evaluation*
Despite the results looks good compared to the Stanford CoreNLP model yet it can be enhanced. But as a first try, it’s not bad.